
Scikit-learnで機械学習(分類)
機械学習などの人工知能の学習では、ただ大量なデータを学習させればよいわけではありません。機械学習の精度は、均質な学習データを与えることによって制度を向上させることができます。
このトライアルでは、人工知能の学習データセットとしてよく利用されるアヤメのデータセットを利用して、データが持つ特長の解析方法について解説します。
アヤメのデータセット(iris-dataset.csv)は、下のダウンロードボタンから取得できます。
Scikit-learnで機械学習(分類)
アヤメのデータは、「がく」と「花びら」の「長さ」と「幅」で構成される4次元のデータです。このままではグラフ化できないため、2次元のデータに変換してみましょう。
主成分分析
データの次元を削除するには、主成分分析(PCA:Principle Component Analysys)を行います。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.decomposition import PCA
from sklearn import svm, metrics
import matplotlib.pyplot as plt
csv = pd.read_csv('iris.csv')
csv_data = csv[["SepalLength","SepalWidth","PetalLength","PetalWidth"]]
csv_label = csv["Name"]
train_data, test_data, train_label, test_label = train_test_split(csv_data, csv_label, test_size=0.30, random_state=1)
clf = svm.SVC()
clf.fit(train_data,train_label)
pre = clf.predict(test_data)
ac_score = metrics.accuracy_score(test_label, pre)
print('正解率=', ac_score)
pca = PCA(n_components=2)
pca.fit(train_data)
train_data = pca.fit_transform(train_data)
labels = train_label.map({'Iris-setosa': 0, 'Iris-versicolor': 1, 'Iris-virginica': 2})
plt.scatter(train_data[:,0],train_data[:,1],c=labels)
plt.show()上記のスクリプトでは、PCA()メソッドのn_componentsで主成分分析の次元を設定します。上記のPythonコードでは、アヤメのデータを4次元から2次元に次元削除する主成分分析を行っています。
labels = train_label.map({'Iris-setosa': 0, 'Iris-versicolor': 1, 'Iris-virginica': 2})
plt.scatter(train_data[:,0],train_data[:,1],c=labels)
plt.show()上記のコード部分では、主成分分析した結果を散布図にプロットしています。なお、アヤメのラベルデータは花の名前が記録されているのですが、このままではプロットの色の塗分けができないため、map()メソッドで花の名前を0~2の整数に数値化しています。
実際に作成されるグラフは以下の通りです。
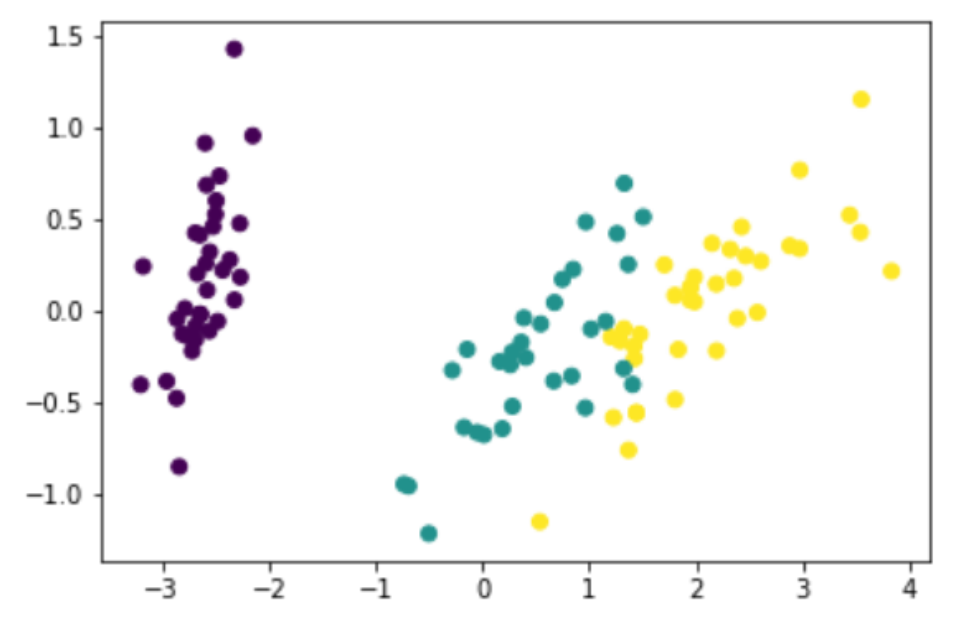
紫色のアヤメは、他のアヤメの種類に比べてデータにはっきりとした特徴があることが主成分分析の結果から理解することができます。一方、緑色と黄色の2種類のアヤメは、一部重なり合った部分があり、この2つのアヤメを分類する場合は、若干精度が低下する可能性があることがわかります。
この重なり合った部分について、2つのアヤメの特長が似ているからなのか、または計測データに誤差が含まれているからなのかをさらに分析することにより、予測精度を向上させることができそうです。
このトライアルで作成した線形分類器モデルの予測精度(正解率)は97.77%となり、ほぼすべてのアヤメを分類可能なレベルに達しています。
