
Scikit-learnで機械学習(画像識別)
Scikit-learn(サーキットラーン)は、個人や商用利用を問わず誰でも無料で利用可能な機械学習フレームワークです。分類、回帰やクラスタリングなどの機能が利用でき、初学者が人工知能を学ぶ際の導入として最適な機械学習フレームワークです。
Scikit-learnで機械学習(画像識別)
このトライアルでは、Scikit-learnのインストールや環境設定に関する説明は省略します。また、プログラムは、Pythonでコーディングしていきます。
学習データの準備
機械学習を行うためには、学習用のデータを準備する必要があります。
MNISTの手書き文字データは、ディープラーニングや機械学習で画像認識する際によく利用されるサンプルデータです。MNISTは、「0~9」の手書き文字の画像データと正解ラベルのデータが収録されています。このデータを利用して、scikit-learnによる機械学習を実践してみましょう。
MNISTの手書き数字のデータベースは、以下のサイトからダウンロードすることができます。

こちらのウェブページから、以下の4つのファイルをダウンロードします。
- train-images-idx3-ubyte.gz
- train-labels-idx1-ubyte.gz
- t10k-images-idx3-ubyte.gz
- t10k-labels-idx1-ubyte.gz
このデータはバイナリデータで、ビックエンディアンで記録されています。
以下のPythonコードを実行すると、バイナリデータから手書き文字データのCSVファイルが作成されます。
- train.csv ⇒ 学習用に使用するデータ
- t10k.csv ⇒ 検証(バリデーション)用データ
- train-0-5.pgm ⇒ 学習用データの1番目のpgm画像データ
- t10k-0-7.pgm ⇒ 検証用データの1番目のpgm画像データ
import struct
def to_csv(name, maxdata):
lbl_f = open("./mnist/" + name + "-labels-idx1-ubyte", "rb")
img_f = open("./mnist/" + name + "-images-idx3-ubyte", "rb")
csv_f = open("./" + name + ".csv", "w", encoding="utf-8")
mag, lbl_count = struct.unpack(">II", lbl_f.read(8))
mag, img_count = struct.unpack(">II", img_f.read(8))
row, cols = struct.unpack(">II", img_f.read(8))
pixels = row * cols
for idx in range(lbl_count):
if idx > maxdata: break
label = struct.unpack("B", lbl_f.read(1))[0]
bdata = img_f.read(pixels)
sdata = list(map(lambda n: str(n), bdata))
csv_f.write(str(label) + ",")
csv_f.write(",".join(sdata) + "\r\n")
if idx < 1:
s = "P2 28 28 255\n"
s += " ".join(sdata)
iname = "./{0}-{1}-{2}.pgm".format(name,idx,label)
with open(iname, "w", encoding="utf-8") as f:
f.write(s)
csv_f.close()
lbl_f.close()
img_f.close()
to_csv('train',1000)
to_csv('t10k',1000)
Pythonで ビッグエンディアン のバイナリデータを読み込むためには、以下のようにします。
mag, lbl_count = struct.unpack(">II", lbl_f.read(8))
struct.unpack()でパックされたバイナリデータとして読み込みます。「>」はビッグエンディアンで読み込むことを示しています。また「II」は、2つ連続したunsined int型(符号なし4バイト整数型)を読み込むことを意味しています。「read(8)」で8バイトづつの塊を読み込んで処理していきます。
| 文字 | バイトオーダ | サイズ | アライメント |
|---|---|---|---|
| @ | native | native | native |
| = | native | 標準 | なし |
| < | リトルエンディアン | 標準 | なし |
| > | ビッグエンディアン | 標準 | なし |
| ! | ネットワーク(=ビッグエンディアン) | 標準 | なし |
| フォーマット | Pythonの型 | サイズ |
|---|---|---|
| c | 長さ1の文字列 | 1バイト |
| b | 整数型 | 1バイト |
| B | 整数型 | 1バイト |
| ? | bool型 | 1バイト |
| h | 整数型 | 2バイト |
| H | 整数型(符号なし) | 2バイト |
| i | 整数型 | 4バイト |
| I | 整数型(符号なし) | 4バイト |
| f | 浮動小数型 | 4バイト |
| d | 浮動小数型 | 8バイト |
for idx in range(lbl_count):
if idx > maxdata: break
label = struct.unpack("B", lbl_f.read(1))[0]
bdata = img_f.read(pixels)
sdata = list(map(lambda n: str(n), bdata))
csv_f.write(str(label) + ",")
csv_f.write(",".join(sdata) + "\r\n")上記のコード部分は、ラベルのデータファイルと手書き文字のデータファイルから、それぞれデータを読み込み、CSVファイルに出力しています。手書き文字データの1文字は、28×28個の符号なし整数データで表現されていますので、pixelsに代入された784(28×28)バイトづつデータを読み込んでいます。
読み込まれた手書き文字の数値データ(0~255)は、map関数とlambda式(無名関数)を用いて1バイトづつ文字列に変換してlist関数で配列に格納しています。
CSVの出力時には、先頭1文字目にラベルデータの数字を出力し、次いでlist関数で配列に格納された手書き文字データの値をjoin関数でカンマ区切りにして出力しています。
MNISTから入手した手書き文字データが、実際どのような手書き文字になっているのか確認してみます。
if idx < 1:
s = "P2 28 28 255\n"
s += " ".join(sdata)
iname = "./{0}-{1}-{2}.pgm".format(name,idx,label)
with open(iname, "w", encoding="utf-8") as f:
f.write(s)
上記のコード部分では、読み込んだ手書き文字データの先頭(一番目)をPGM(Portable GrayMap format)画像形式で出力しています。このPythonコードでは、学習用データの「train-0-5.pgm」と検証用データの「t10k-0-7.pgm」の2つのPGM画像ファイルが出力されますので、PGM画像を表示できるビューアで確認することができます。
IrfanView(フリーソフト)で画像を表示してみます。
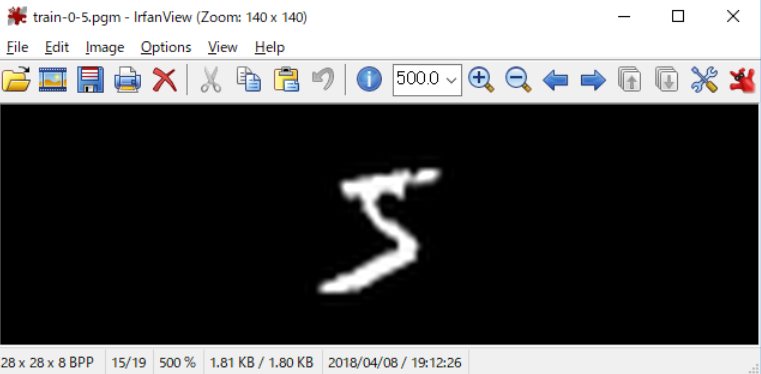
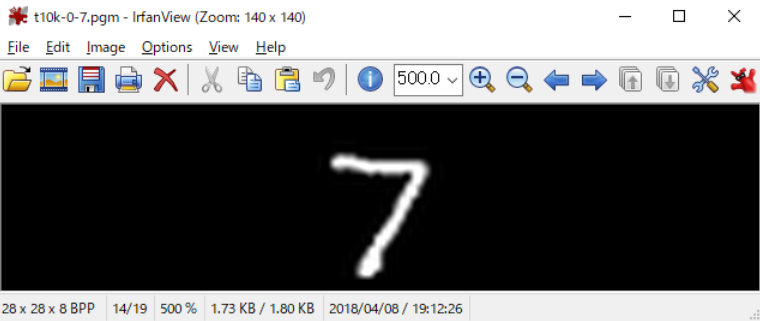
このトライアルでは、「5」と「7」の手書き文字が表示されました。このデータを使用してscikit-learnで機械学習を行います。
手書き文字画像を学習させる
今回作成した学習用データは、ラベルデータ(答え)と画像データがセットになっています。答えがわかっているものに対する学習のことを「教師あり学習」と言います。
from sklearn import svm, metrics
from sklearn.model_selection import train_test_split
def read_csv(flnm):
labels = []
images = []
with open(flnm, "r") as f:
for line in f:
cols = line.split(",")
labels.append(int(cols.pop(0)))
vals = list(map(lambda n: int(n) / 256, cols))
images.append(vals)
return {"labels":labels, "images":images}
data = read_csv("./train.csv")
test = read_csv("./t10k.csv")
clf = svm.SVC()
clf.fit(data["images"], data["labels"])
predict = clf.predict(test["images"])
ac_score = metrics.accuracy_score(test["labels"], predict)
cl_report = metrics.classification_report(test["labels"], predict)
print("正解率=", ac_score)
print(cl_report)上記のPythonコードで機械学習ができてしまいます。人工知能とか聞くと難しく感じてしまいがちですが、Pythonと人工知能フレームワークを利用することで、比較的簡単に実践することができるのです。
def read_csv(flnm):
labels = []
images = []
with open(flnm, "r") as f:
for line in f:
cols = line.split(",")
labels.append(int(cols.pop(0)))
vals = list(map(lambda n: int(n) / 256, cols))
images.append(vals)
return {"labels":labels, "images":images}上記のコード部分は、学習用とテスト用のCSVデータを読み込むための関数です。読み込んだCSVの先頭にラベルデータ(答え)が記録され、続いて手書き文字画像データを構成する784個(28×28個)のデータが記録されています。
このCSVデータを先頭から一行ずつ読み込み、ラベルデータと画像データに分離して、それぞれ配列変数に格納していきます。行の先頭にあるラベルデータは、pop()メソッドで取り出しています。また、lambda式(無名)で画像データの階調を256で割って規格化(または正規化)しています。
data = read_csv("./train.csv")
test = read_csv("./t10k.csv")
clf = svm.SVC(kernel='linear')
clf.fit(data["images"], data["labels"])
predict = clf.predict(test["images"])
ac_score = metrics.accuracy_score(test["labels"], predict)
cl_report = metrics.classification_report(test["labels"], predict)
print("正解率=", ac_score)
print(cl_report)先に定義したread_csv()関数を呼び出してデータを読み込み、学習用データを「data」、テスト用データを「test」という名前の配列変数に格納しています。
分類器は、SVC(SVM Classification)を使用します。SVM(サポートベクターマシーン)は、2つのデータ間のマージン(離隔距離)を最大化するように分類化する分類器です。このトライアルでは、線形分類による手書き画像データの学習をすすめていきます。
fit()メソッドに手書き画像の学習データとラベルデータを与えて学習を行います。次に、predict()メソッドに手書き画像のテストデータを入力して、予測結果を出力しています。
accuracy_score()メソッドで予測したテストデータのラベルデータと予測結果を比較して、正解率を算出します。最後にclassification_report()メソッドで予測結果の分析値を出力しています。
機械学習の成果を確認する
$python3.6 mnist-train.py
正解率= 0.868263473054
precision recall f1-score support
0 0.91 0.93 0.92 42
1 0.97 1.00 0.99 67
2 0.86 0.93 0.89 55
3 0.84 0.80 0.82 46
4 0.89 0.89 0.89 55
5 0.72 0.84 0.78 50
6 0.95 0.86 0.90 43
7 0.80 0.84 0.82 49
8 0.91 0.72 0.81 40
9 0.84 0.80 0.82 54
avg / total 0.87 0.87 0.87 501上記の結果は、1,000件の学習用データと500件のテストデータをによる実験結果です。それぞれ「0~9」のラベルデータの予測スコアと全体の平均的スコアが表示されています。
この時点で既に全体の正解率は87%に達しています。個別にみてみると「5」は、他のラベルに比べて予測がやや難しいことがみてとれます。
各カラムの意味は以下の通りです。
- precision⇒精度(正解と予測したデータの内、実際に正解したものの割合)
- recall⇒再現率(正解と予測されるべきものに対して、実際に正解したものの割合)
- f1-score⇒F尺度(精度と再現率に調和平均)
- support⇒対象の数
次に学習データ数を増やしてみましょう。10,000件の学習用データと5000件のテストデータにより実験してみます。学習データが増えたので、学習に多少時間が掛かります。
正解率= 0.868263473054
正解率= 0.891821635673
precision recall f1-score support
0 0.92 0.97 0.94 460
1 0.93 0.99 0.96 571
2 0.88 0.89 0.88 530
3 0.82 0.89 0.85 501
4 0.88 0.92 0.90 500
5 0.88 0.81 0.84 456
6 0.93 0.91 0.92 462
7 0.90 0.87 0.89 512
8 0.88 0.82 0.85 489
9 0.90 0.84 0.87 520
avg / total 0.89 0.89 0.89 5001学習データを増やした結果、全体の正解率は89%に向上しました。また、「5」は72%から88%に正解率が向上したことが確認できます。このように学習データを増やすと正解率が向上することがわかりました。
ただし、学習データを増やし過ぎると逆に正解率が低下する場合もあります。これを過学習(オーバーフィッティング)と言います。
機械学習などの人工知能の精度を向上させるためには、たくさんのデータを学習させる必要がありますが、何でもよいというわけではなく、均質なデータを学習させることも重要なのです。

