
Scikit-learnで機械学習(ランダムフォレスト)
ランダムフォレストとは、決定木を複数設定して、各決定木の予測結果から多数決で最終的な予測結果を決定する方法です。このような方法をアンサンブル学習と呼びます。
複数の決定木(tree)がまるで森を形成するようなイメージからランダムフォレストと名付けられています。
Scikit-learnで機械学習(ランダムフォレスト)
お馴染みのアヤメのデータを使用して、ランダムフォレストを実践してみます。
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn import tree, metrics
from sklearn.model_selection import train_test_split
import pydotplus as pdp
from sklearn.externals.six import StringIO
csv = pd.read_csv('iris.csv')
csv_data = csv[["SepalLength","SepalWidth","PetalLength","PetalWidth"]]
csv_label = csv["Name"]
train_data, test_data, train_label, test_label = \
train_test_split(csv_data, csv_label, test_size=0.3, random_state=1)
clf = RandomForestClassifier()
clf.fit(train_data,train_label)
pre = clf.predict(test_data)
ac_score = metrics.accuracy_score(test_label, pre)
cl_report = metrics.classification_report(test_label, pre)
print('正解率=', ac_score)
print(cl_report)
print('特徴量:')
print(clf.feature_importances_)
dot_data = StringIO()
for i, val in enumerate(clf.estimators_):
tree.export_graphviz(clf.estimators_[i], out_file='tree_%d.dot'%i)
graph = pdp.graph_from_dot_file('tree_%d.dot'%i)
graph.write_png('tree_%d.png'%i)ランダムフォレストの学習器の設定、学習及び予測については以下の通りです。
clf = RandomForestClassifier()
clf.fit(train_data,train_label)
pre = clf.predict(test_data)RandomForestClassifier()のハイパーパラメータには、ランダムフォレストを形成する決定木の本数(n_estimators)、個々の決定木を分割する基準(criterion)や決定木でも実験したそれぞれの決定木の階層(max_depth)などを設定することができます。
正解率= 0.955555555556
precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 14
Iris-versicolor 0.94 0.94 0.94 18
Iris-virginica 0.92 0.92 0.92 13
avg / total 0.96 0.96 0.96 45
特徴量:
[ 0.06408955 0.03076023 0.3522496 0.55290062]正解率は、95.55%ですね。特徴量として4つの数値が表示されていますが、これは、ランダムフォレストのアンサンブル学習から得られた重要変数の重みを表しています。
feature_importances_から、特徴量の重要度を出力することができます。アヤメのデータは、「がくの長さ」、「がくの幅」、「花びらの長さ」と「花びらの幅」が与えられています。数値の左から3番目と4番目が大きいですね。つまり、「花びらの幅」と「花びらの長さ」が重要な問題変数であることが理解できましたね。
次にランダムフォレストのそれぞれの決定木を見てみましょう。
ランダムフォレストのそれぞれの決定木を画像に出力している部分は以下の通りです。pydotplusとgraphvisを使って、それぞれの決定木の構造をPNG形式の画像で出力しています。今回のトライアルでは、ランダムフォレストを構成する決定木の本数は設定しませんでしたので、10本の決定木が出力されました。
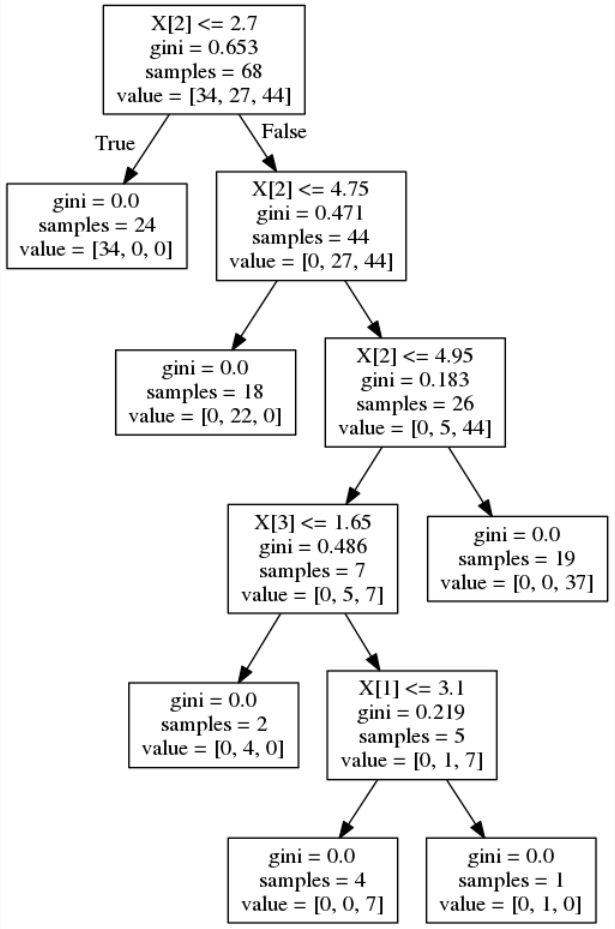
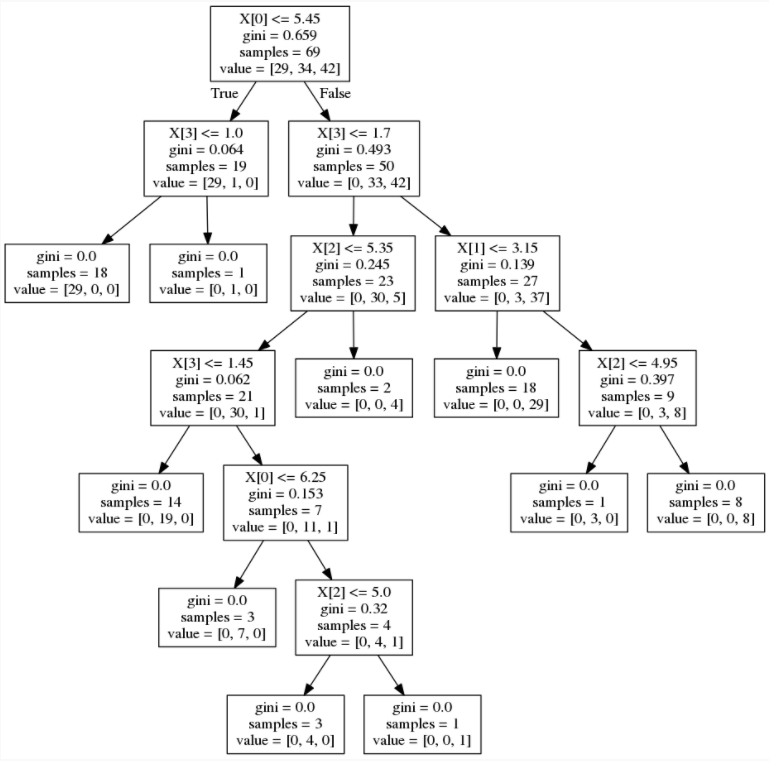
この回では、scikit-learnを使用してアンサンブル学習アルゴリズムのランダムフォレストと、特徴量の重要度の分析について見てきました。
機械学習だけでも、かなり広範囲の分野でイノベーションが期待できそうです。

