
Keras+TensorFlowで実践CNN(その3)
カラー画像から被写体を識別する
前回は、グレースケール画像から被写体の動物の識別実験を行いました。
今回は、カラー画像(RGB画像)をCNNに入力して、被写体の識別実験を行います。カラー画像の作り方については、以下を参照してください。
グレースケールのコードを少し改良する
前回作成したグレースケールのコードを少しだけ改良します。
import keras
from keras.models import Sequential
from keras.layers import Convolution2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
from keras.utils.visualize_util import plot
import numpy as np
import sys
categories = ["panda","wild_cat","rhino","elephant","flamingo","platypus","okapi","llama","kangaroo","hedgehog","emu","beaver"]
num_class = len(categories)
img_width = 64
img_height = 64
#読み込んだ画像データを正規化する
train_data, test_data, train_label, test_label = np.load("./images/wildlife_rgb.npy")
train_data = train_data.astype("float32") / 256
test_data = test_data.astype("float32") / 256
#カラー画像は、Convolutio2Dに入力するための次元操作は必要なし
#グレースケール画像をConvolutio2Dに入力するための次元操作
#train_newarray = (train_data.shape[0], train_data.shape[1], train_data.shape[1], 1)
#train_data = np.reshape(train_data, train_newarray)
#test_newarray = (test_data.shape[0], test_data.shape[1], test_data.shape[1], 1)
#test_data = np.reshape(test_data, test_newarray)
#モデルの設定
model = Sequential()
#畳み込み層の設定
model.add(Convolution2D(32, 3, 3, border_mode='same',
input_shape=train_data.shape[1:], name='Conv2D-1'))
model.add(Activation('relu'))
#プーリング層の設定
model.add(MaxPooling2D(pool_size=(2,2),name='MaxPool-1'))
model.add(Dropout(0.25, name='Dropout-1'))
#全結合層の設定
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5, name='Dropout-2'))
#出力層の設定
model.add(Dense(num_class, input_dim=512))
model.add(Activation('softmax'))
#モデルの構築
model.compile(loss = 'binary_crossentropy',
optimizer = 'rmsprop',
metrics = ['accuracy'])
#モデルプロットとTensorBoardの出力設定
plot(model, to_file="model.png", show_shapes=True)
log_filepath = "./log_dir/"
tb_cb = keras.callbacks.TensorBoard(log_dir=log_filepath, histogram_freq=1,
write_graph=True, write_images=True)
#学習実行
model.fit(train_data, train_label, verbose=1, callbacks=[tb_cb],
nb_epoch=50, batch_size=2)
#validation_data=(test_data,test_label))
#テストデータで評価する
score = model.evaluate(test_data, test_label, verbose=0)
print("loss=", score[0])
print("accuracy=", '{0:.2f}'.format(score[1]))Convolution2Dの入力は4次元テンソルです。カラー画像は、赤、緑及び青の3種類のデータで構成されているため、データファイルのシェープは既に(入力画像数、縦ピクセル、横ピクセル、RGBレイヤ数)になっていますので、そのままConvolution2Dに入力することができます。このため、前回のグレースケール画像で行ったデータの次元変更処理は必要ありませんので、すべてコメントアウトしました。
#カラー画像は、Convolutio2Dに入力するための次元操作は必要なし
#グレースケール画像をConvolutio2Dに入力するための次元操作
#train_newarray = (train_data.shape[0], train_data.shape[1], train_data.shape[1], 1)
#train_data = np.reshape(train_data, train_newarray)
#test_newarray = (test_data.shape[0], test_data.shape[1], test_data.shape[1], 1)
#test_data = np.reshape(test_data, test_newarray)作成したグラフは以下の通りです。一番先頭の畳み込み層(convolution2D_input1:InputLayer)の入力データのシェープが(None,64,64,3)になっていることが確認できます。
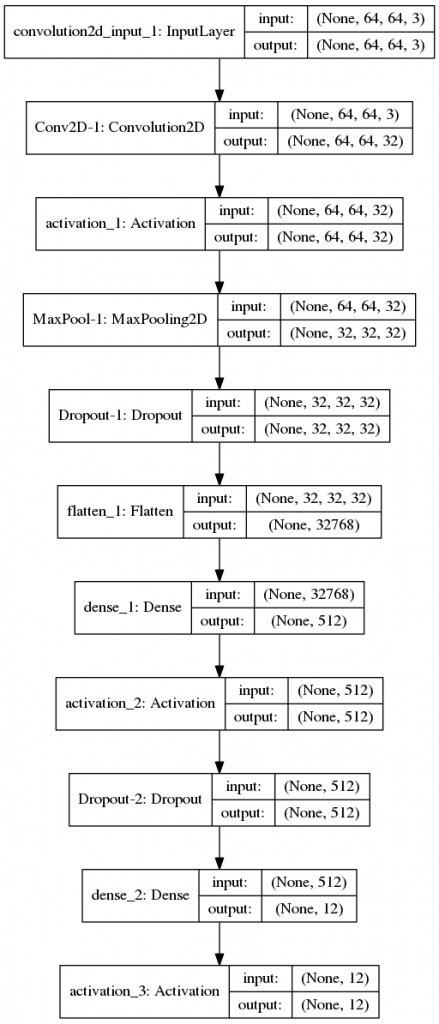
では、RGB(カラー)画像をCNNに入力して、訓練用データによる学習とテスト用データによる予測精度を見てみましょう。
Epoch 40/50
456/456 [==============================] - 66s - loss: 2.0895e-04 - acc: 1.0000
Epoch 41/50
456/456 [==============================] - 66s - loss: 1.3470e-07 - acc: 1.0000
Epoch 42/50
456/456 [==============================] - 65s - loss: 3.1692e-06 - acc: 1.0000
Epoch 43/50
456/456 [==============================] - 65s - loss: 0.0018 - acc: 0.9996
Epoch 44/50
456/456 [==============================] - 65s - loss: 5.6192e-05 - acc: 1.0000
Epoch 45/50
456/456 [==============================] - 65s - loss: 2.3978e-04 - acc: 1.0000
Epoch 46/50
456/456 [==============================] - 64s - loss: 1.1287e-07 - acc: 1.0000
Epoch 47/50
456/456 [==============================] - 66s - loss: 3.4264e-07 - acc: 1.0000
Epoch 48/50
456/456 [==============================] - 66s - loss: 1.0917e-07 - acc: 1.0000
Epoch 49/50
456/456 [==============================] - 65s - loss: 1.8419e-07 - acc: 1.0000
Epoch 50/50
456/456 [==============================] - 65s - loss: 1.0441e-07 - acc: 1.0000
loss= 0.866788074678
accuracy= 0.90グレースケール画像の実験と同様に、エポック数の終盤では正解率が100%になっています。テストデータによる検定では、正解率は90%になりました。
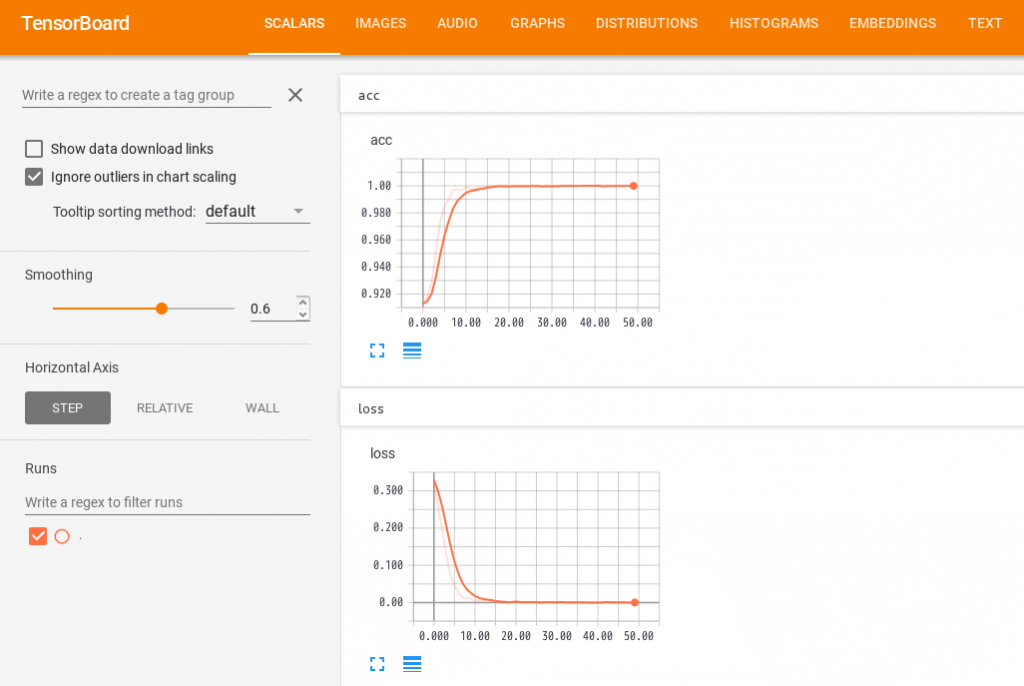
こちらもグレースケール画像の実験と同様に、学習中の正解率(上)と損失のグラフ(下)は理想的な形状ですが、やはりテスト用データによる損失の大きさと正解率との乖離が大きいので、過学習の可能性がありそうです。
RGB(カラー)画像を入力したことにより情報量が増えたため、グレースケール画像の予測精度とカラー画像の予測精度に差異が生じるのではと予想していましたが、結果はそうなりませんでした。
入力する画像のピクセル数を変更したり、CNNの層を深化してどのように変化するのか実験してみる価値がありそうです。
今回は、RGB(カラー)画像データを入力してCNNによる画像識別の実験を行いました。次回は、入力する画像のピクセル数を変更したり、CNNの層を深化させたりして実験してみたいとおもいます。