
TensorFlowで実践ディープラーニング(その4)
ディープラーニングで分類する
今回は、MNISTの手書き文字をKeras+TensorFlowで分類してみます。MNISTの手書き文字はバイナリデータなので、いったんCSVファイルに出力してから、それを読み込んで学習していきます。
MNISTの手書きデータの加工については、以下を参照してください。
MNISTの手書き文字は、28×28ピクセルの256階調モノクロ(白黒)のデータセットです。PGMフォーマットに出力して下図のように可視化することも可能です。今回は、6万件の手書きデータセットを使用して、学習と交差検証を行っていきます。
分類問題のコーディング
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
import keras
from keras.models import Sequential
from keras.layers.core import Dense, Activation, Dropout
from keras.utils import np_utils
from keras.optimizers import Adam
#データ読込み、訓練用とテスト用データの分割処理
csv = pd.read_csv('train.csv', header=None)
csv_data = csv.ix[ :, 1: ] #データマトリクスの抽出
csv_label = csv.ix[ :, 0 ] #データラベルの抽出
train_data, test_data, train_label, test_label = \
train_test_split(csv_data, csv_label, test_size=0.3, shuffle=True)
#numpy.ndarrayにfloat32型で変換する
#as_matrix()じゃなくてvaluesでもOKだよ
train_data = train_data.as_matrix().astype('float32')
test_data = test_data.as_matrix().astype('float32')
#正規化する
train_data /= 255.0
test_data /= 255.0
#One-hotカテゴリにfloat32型で変換する
train_label = np_utils.to_categorical(train_label.as_matrix()).astype('float32')
test_label = np_utils.to_categorical(test_label.as_matrix()).astype('float32')
#モデルの構造を定義する
model = Sequential()
model.add(Dense(512, input_dim=784))
model.add(Activation('relu'))
model.add(Dropout(0.2))
model.add(Dense(512, input_dim=512))
model.add(Activation('relu'))
model.add(Dropout(0.2))
model.add(Dense(10, input_dim=512))
model.add(Activation('softmax'))
#TensorBoardに表示するための設定
log_filepath = "./log_dir/"
tb_cb = keras.callbacks.TensorBoard(log_dir=log_filepath, histogram_freq=1,
write_graph=True, write_images=True)
#モデルを構築する
model.compile(loss = 'categorical_crossentropy',
optimizer = Adam(),
metrics = ['accuracy'])
#モデルを訓練する
model.fit(train_data, train_label, verbose=1, callbacks=[tb_cb],
nb_epoch=100, batch_size=512,
validation_data=(test_data,test_label))
#テストデータで評価する
score = model.evaluate(test_data, test_label, verbose=0)
print("loss=", score[0])
print("accuracy=", '{0:.2f}'.format(score[1]))では、ポイントについて解説していきます。まずは、データの加工についてです。
#データ読込み、訓練用とテスト用データの分割処理
csv = pd.read_csv('train.csv', header=None)
csv_data = csv.ix[ :, 1: ] #データマトリクスの抽出
csv_label = csv.ix[ :, 0 ] #データラベルの抽出
train_data, test_data, train_label, test_label = \
train_test_split(csv_data, csv_label, test_size=0.3, shuffle=True)
#numpy.ndarrayにfloat32型で変換する
#as_matrix()じゃなくてvaluesでもOKだよ
train_data = train_data.as_matrix().astype('float32')
test_data = test_data.as_matrix().astype('float32')
#正規化する
train_data /= 255.0
test_data /= 255.0
#One-hotカテゴリにfloat32型で変換する
train_label = np_utils.to_categorical(train_label.as_matrix()).astype('float32')
test_label = np_utils.to_categorical(test_label.as_matrix()).astype('float32')
[/python]基本的にPandasでCSVを読み込んでから、ラベルとデータをインデックス番号で抽出します。ラベルは、先頭0番目に配置されています。画像データは、1番目以降の784個(28個×28個)連続した数値となります。ラベルとデータを抽出したら、train_test_split()メソッドで、訓練用データとテスト用データに分解します。
訓練用データとテスト用データは、float32型に型変換してnumpy.ndarrayに入れます。その後、更に255で割って正規化します。訓練用ラベルとテスト用ラベルも、float32型に型変換、One-hotベクトルに変換してnumpy.ndarrayに入れます。ちなみにfloat32型に型変換しているのは、メモリ消費量を小さくして計算効率をよくするためです。ただし、アーキテクチャに依存するので絶対とは言うことができません。
次にモデルの構造を定義していきます。
#モデルの構造を定義する
model = Sequential()
model.add(Dense(512, input_dim=784))
model.add(Activation('relu'))
model.add(Dropout(0.2))
model.add(Dense(512, input_dim=512))
model.add(Activation('relu'))
model.add(Dropout(0.2))
model.add(Dense(10, input_dim=512))
model.add(Activation('softmax'))モデルは、「入力層」-「隠れ層1」-「隠れ層2」-「出力層」のニューラルネットワークとなります。隠れ層の活性化関数はReLUを使用し、出力層の直前ではsoftmaxを適用しています。入力は画像ピクセル数の784(28×28)、各隠れ層のノード数は512で、最終的に10個の出力が得られる構造となっています。
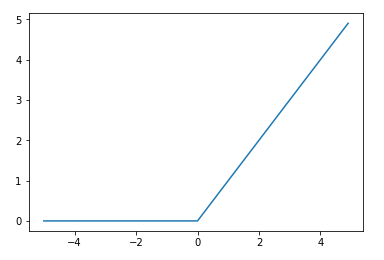
ReLU(Rectified Linear Unit)は、活性化関数の一つで、X > 0の部分では微分した値が常に1となるため、勾配消失が発生しない関数です。勾配損失とは、多層構造型ニューラルネットワークで隠れ層を増やしていくと、誤差逆伝搬法による損失関数の勾配が、入力層に到達する前にほぼ0になってしまうことです。ReLUのグラフは以下の通りです。
では、モデル構築して実際に学習を行います。
#モデルを構築する
model.compile(loss = 'categorical_crossentropy',
optimizer = Adam(),
metrics = ['accuracy'])
#モデルを訓練する
model.fit(train_data, train_label, verbose=1, callbacks=[tb_cb],
nb_epoch=100, batch_size=512,
validation_data=(test_data,test_label))
#テストデータで評価する
score = model.evaluate(test_data, test_label, verbose=0)
print("loss=", score[0])
print("accuracy=", '{0:.2f}'.format(score[1]))損失関数は、categorical_crossentropy(多クラス交差エントロピー)を設定しています。オプティマイザは、Adam(Adaptive Moment Estimation)を設定しています。Adamは、sgd(確率的勾配降下法)よりも収束が早く、他のオプティマイザよりも最適化されたオプティマイザらしいです。
学習と汎化性能の確認
今回は、4万2千件の手書き文字データを使用して学習するため、反復訓練の回数(エポック数)は100回、バッチサイズは512に設定しています。実験に使用したサーバは、4コアCPU×1基のマシンなので、控えめに設定しています。
では、結果を確認してみましょう。
42000/42000 [==============================] - 9s - loss: 0.0043 - acc: 0.9986 - val_loss: 0.0928 - val_acc: 0.9843
Epoch 92/100
42000/42000 [==============================] - 9s - loss: 0.0075 - acc: 0.9978 - val_loss: 0.1000 - val_acc: 0.9831
Epoch 93/100
42000/42000 [==============================] - 9s - loss: 0.0051 - acc: 0.9982 - val_loss: 0.0904 - val_acc: 0.9836
Epoch 94/100
42000/42000 [==============================] - 9s - loss: 0.0050 - acc: 0.9984 - val_loss: 0.0917 - val_acc: 0.9839
Epoch 95/100
42000/42000 [==============================] - 9s - loss: 0.0034 - acc: 0.9989 - val_loss: 0.0883 - val_acc: 0.9859
Epoch 96/100
42000/42000 [==============================] - 9s - loss: 0.0029 - acc: 0.9991 - val_loss: 0.1039 - val_acc: 0.9822
Epoch 97/100
42000/42000 [==============================] - 9s - loss: 0.0043 - acc: 0.9987 - val_loss: 0.0939 - val_acc: 0.9833
Epoch 98/100
42000/42000 [==============================] - 9s - loss: 0.0028 - acc: 0.9990 - val_loss: 0.0952 - val_acc: 0.9834
Epoch 99/100
42000/42000 [==============================] - 9s - loss: 0.0035 - acc: 0.9989 - val_loss: 0.1001 - val_acc: 0.9833
Epoch 100/100
42000/42000 [==============================] - 9s - loss: 0.0121 - acc: 0.9967 - val_loss: 0.1051 - val_acc: 0.9828
loss= 0.10511202487
accuracy= 0.98100回の反復学習では99.6%の正解率をマーク、テスト用データでも98%の正解率が出ました。
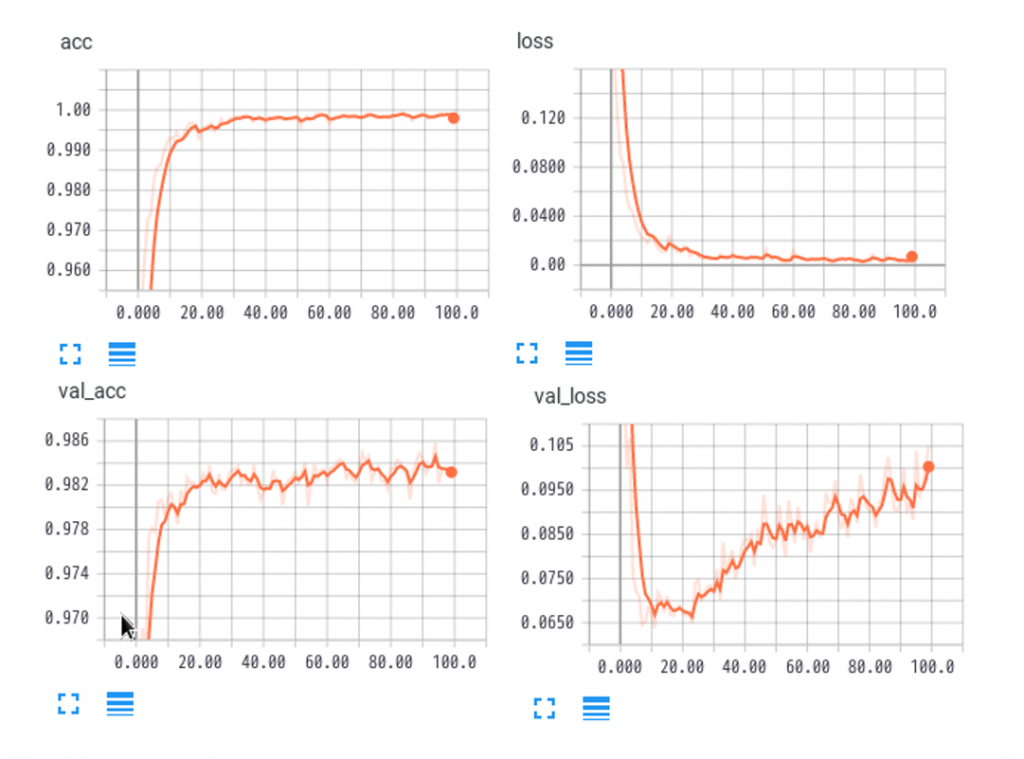
学習時における精度(acc)と損失(loss)のグラフは、理想的な形をしているように見えます。一方、交差検証における精度(val_acc)と損失(val_loss)のグラフでは、特に損失が学習回数と共に増加していることがわかります。
今回のまとめ
今回は、Keras+TensorFlowを使用して、MNISTの手書き文字を分類する実験を行いました。
処理するデータ量が増加することで、計算時間(計算コスト)も大幅に増加することがわかりました。今後ディープラーニングの開発を進めていく上では、改めてGPUの必要性を感じたところです。
深層学習に必要なデータ加工、モデル設定や反復学習に関する基本的事項を4回に渡って体験してきました。関連書籍を読んだだけではよく理解できないことも、実際に体験を交えて学習することで格段に理解が深まります。
人工知能やってみたい人や何から始めたらよいかわからない人に対して、モチベーション維持の一助となれば幸いです。