
Keras+TensorFlowで実践CNN(その6)
人工知能はどのように画像を捉えているのか
人工知能(AI)の画像識別を飛躍的に向上させた畳み込みニューラルネットワーク(CNN)は、複数の畳み込み層やプーリング層の処理を介して特徴量を濃縮させていくイメージですが、実際のところどのようになっているのか気になりますよね。
人間が画像の被写体を識別する場合は、視覚を通じて形、色などの特徴や周囲の状況と記憶を照合して総合的に判断します。一方、AIは視覚の代わりに画像をデータとして入力し処理を行います。そうは言っても、AIが画像をどうやって識別しているのか、まったくイメージできませんよね。
そこで今回は、CNNの畳み込み層やプーリング層の処理を可視化して、AIがどのように画像をどのように捉えているのかを確認してみまたいとおもいます。
CNNの各処理層の処理のおさらい
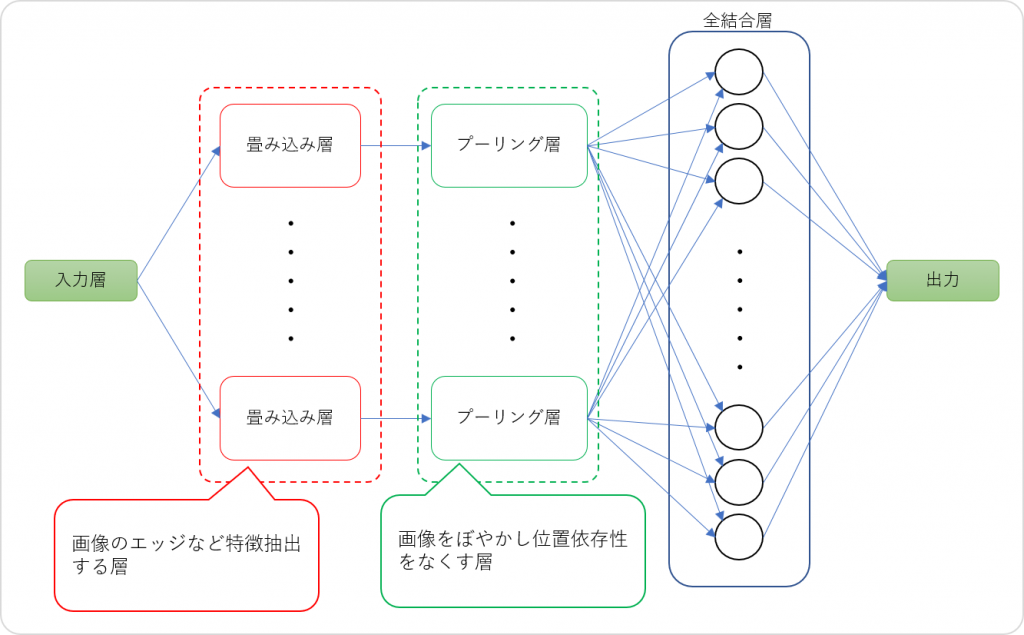
畳み込みニューラルネットワーク(CNN)に入力された画像データは、「畳み込み層」で特徴を抽出するためのフィルタを通じて、画像から濃淡のパターンなどエッジ(特徴)が抽出されます。これを「特徴マップ」と言います。
その後、「プーリング層」では、前の「畳み込み層」の処理から得られた「特徴マップ」を縮小して画像をぼやかします。この処理を行うことにより位置依存性をなくし、特徴量の位置が多少ずれていたとしても、ズレを許容して識別することを可能にしています。プーリングの方法には、最大プーリングと平均プーリングがあります。
CNNの概略図は、以下の通りです。
Kerasで特徴マップを出力させる
では、CNNモデルの各層の特徴マップを可視化してみましょう。
特徴マップは、Kerasバックエンドを利用します。以下のスクリプトでは、function()メソッドでCNNモデルから各処理層で処理された画像データを取得しています。function()メソッドの戻り値はnumpyの配列です。
from keras import backend as K
import matplotlib.pyplot as plt
#中間層の特徴マップを出力する
def middle_layer_output(numlay, INPDATA):
get_layer = K.function([model.layers[0].input], [model.layers[numlay].output])
layer_output_comp = get_layer([INPDATA])[0]
print(layer_output_comp.shape)
#sys.exit()
dim_n = layer_output_comp.shape[0]
dim_x = layer_output_comp.shape[1]
dim_y = layer_output_comp.shape[2]
dim_z = layer_output_comp.shape[3]
#中間層の出力を図化する
plt.figure()
for num_pic in range(dim_n):
for num_map in range(dim_z):
img = layer_output_comp[num_pic, :, :, num_map]
img = Image.fromarray(np.uint8(img))
plt.subplot(8,8,num_map+1)
plt.axis('off')
plt.imshow(img, cmap='gray')
plt.savefig('Layer' + str(numlay) + '_input' + str(num_pic) + '.png')
middle_layer_output(0, X)取得したnumpy配列のデータをPILのImage.fromarray()メソッドで画像データに変換して、matplotlibでファイルに出力させています。関数の呼び出し時の引数は、第1引数に見たい特徴マップの層の番号、第2引数には予測データ(numpy配列のなっている画像データ)を付与します。この方法では、特徴マップをカラー画像として出力することはできないので、グレースケールで画像を出力しています。
コードの全体は以下の通りです。
import keras
from keras.models import load_model, Model
from keras import backend as K
from PIL import Image
import numpy as np
import h5py
import sys, os
if len(sys.argv) < = 1:
print("USAGE: python3.6 caltech101_keras5.py (ファイル名)")
quit()
#画像カテゴリの設定
categories1 = ["panda","wild_cat","rhino","elephant","flamingo","platypus","okapi","llama","kangaroo","hedgehog","emu","beaver"]
categories2 = ["パンダ","ヤマネコ","サイ","象","フラミンゴ","カモノハシ","オカピ","ラマ","カンガルー","ハリネズミ","エミュ","ビーバー"]
#予測対象の画像を入力形式に変換する
img_width = 64
img_height = 64
X = []
files = []
for flname in sys.argv[1:]:
img = Image.open(flname)
img = img.convert("RGB")
img = img.resize((img_width, img_height))
data = np.asarray(img)
X.append(data)
files.append(flname)
X = np.array(X)
#モデルの読込み
model = load_model('wildlife_rgb_adam.h5')
#model = load_model('./wildlife_rgb_rev01.h5')
#予測処理
predict = model.predict(X, verbose=1)
model.summary()
import matplotlib.pyplot as plt
#from sklearn.preprocessing import MinMaxScaler
#中間層の特徴マップを出力する
def middle_layer_output(numlay, INPDATA):
get_layer = K.function([model.layers[0].input],[model.layers[numlay].output])
layer_output_comp = get_layer([INPDATA])[0]
print(layer_output_comp.shape)
sys.exit()
dim_n = layer_output_comp.shape[0]
dim_x = layer_output_comp.shape[1]
dim_y = layer_output_comp.shape[2]
dim_z = layer_output_comp.shape[3]
#中間層の出力を図化する
plt.figure()
for num_pic in range(dim_n):
for num_map in range(dim_z):
img = layer_output_comp[num_pic, :, :, num_map]
img = Image.fromarray(np.uint8(img))
plt.subplot(8,8,num_map+1)
plt.axis('off')
plt.imshow(img, cmap='gray')
plt.savefig('Layer' + str(numlay) + '_input' + str(num_pic) + '.png')
middle_layer_output(0, X)
middle_layer_output(14, X)
#予測結果をhtmlで出力する
def html_output(pre, fls, cat1, cat2):
out = ""
for idx, pre in enumerate(predict):
y = np.argmax(pre)
out += "<hr><h3>入力:" + fls[idx] + "</h3>"
out += "<p><img src='./test_images/" + os.path.basename(fls[idx]) + \
"' width=150</p>"
out += "</p><p>予測結果:" + cat2[y] + "(" + cat1[y] + ")</p>"
html_out = "<html><body style='text-align:center;'>" + \
"<style>p{margin:0; padding:0;}</style></body><body>" + out + "</body></html>"
#html文をファイル出力する
with open("CNN_predict_result.html", "w") as f:
f.write(html_out)
html_output(predict, files, categories1, categories2)上記のスクリプトは、既に学習済みのモデルを読み込んでから予測するようになっています。詳しくは、こちらを参照してみてください。
AIが見ているもの
では、CNNモデルの各層の特徴マップを可視化してみましょう。今回は、1番目の「畳み込み層」と一番最後の「マックスプーリング層」を可視化してみます。モデル構造は以下の通りです。
1/1 [==============================] - 0s
____________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
====================================================================================================
Conv2D-1 (Convolution2D) (None, 64, 64, 64) 1792 convolution2d_input_1[0][0]
____________________________________________________________________________________________________
activation_1 (Activation) (None, 64, 64, 64) 0 Conv2D-1[0][0]
____________________________________________________________________________________________________
MaxPool-1 (MaxPooling2D) (None, 32, 32, 64) 0 activation_1[0][0]
____________________________________________________________________________________________________
Conv2D-2 (Convolution2D) (None, 32, 32, 64) 36928 MaxPool-1[0][0]
____________________________________________________________________________________________________
activation_2 (Activation) (None, 32, 32, 64) 0 Conv2D-2[0][0]
____________________________________________________________________________________________________
MaxPool-2 (MaxPooling2D) (None, 16, 16, 64) 0 activation_2[0][0]
____________________________________________________________________________________________________
Conv2D-3 (Convolution2D) (None, 16, 16, 64) 36928 MaxPool-2[0][0]
____________________________________________________________________________________________________
activation_3 (Activation) (None, 16, 16, 64) 0 Conv2D-3[0][0]
____________________________________________________________________________________________________
MaxPool-3 (MaxPooling2D) (None, 8, 8, 64) 0 activation_3[0][0]
____________________________________________________________________________________________________
Conv2D-4 (Convolution2D) (None, 8, 8, 64) 36928 MaxPool-3[0][0]
____________________________________________________________________________________________________
activation_4 (Activation) (None, 8, 8, 64) 0 Conv2D-4[0][0]
____________________________________________________________________________________________________
MaxPool-4 (MaxPooling2D) (None, 4, 4, 64) 0 activation_4[0][0]
____________________________________________________________________________________________________
flatten_1 (Flatten) (None, 1024) 0 MaxPool-4[0][0]
____________________________________________________________________________________________________
dense_1 (Dense) (None, 1024) 1049600 flatten_1[0][0]
____________________________________________________________________________________________________
activation_5 (Activation) (None, 1024) 0 dense_1[0][0]
____________________________________________________________________________________________________
dense_2 (Dense) (None, 256) 262400 activation_5[0][0]
____________________________________________________________________________________________________
activation_6 (Activation) (None, 256) 0 dense_2[0][0]
____________________________________________________________________________________________________
dense_3 (Dense) (None, 12) 3084 activation_6[0][0]
____________________________________________________________________________________________________
activation_7 (Activation) (None, 12) 0 dense_3[0][0]
====================================================================================================
Total params: 1,427,660
Trainable params: 1,427,660
Non-trainable params: 0以下は、1番目の「折りたたみ層」の特徴マップです。

以下は、最後の「マックスプーリング層」の特徴マップです。

今回のモデルでは、各畳み込み層では64個のフィルタを設定していますので、特徴マップも64枚出力されています。
最初の特徴マップでは、人間の目で見ても被写体が何であるかはある程度は判断できるものもあります。しかしながら、最後の特徴マップでは、被写体が何であるかは人間では理解することは不可能です。AIは画像をこのように捉えているのです。
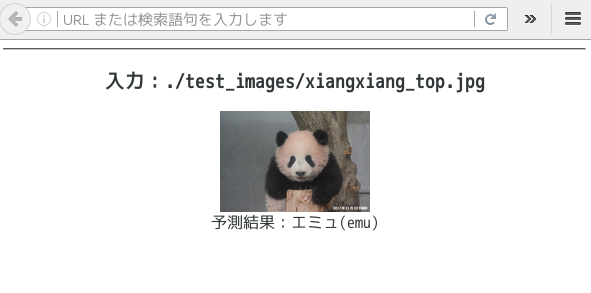
パンダなのにエミュと予測されており、間違った答えを返しています。そう簡単にはいかないようですね。
今回のまとめ
今回は、CNNの各層で画像がどのように処理されているのかを、Kerasバックエンドを使用して取り出し可視化してみました。AIが画像をどのように捉えているのか理解いただけたものとおもいます。
いたずらに中間層を増やしたところで、元画像から特徴量を上手く抽出することができなければ予測精度を向上させることは難しいかもしれません。もう少し画像数を増やして学習させたり、入力画像のピクセル数も増やしてみたり、さらには中間層を減らしてみたりと、やらなければならないことがたくさんありそうです。
