
Scikit-learnで機械学習(決定木)
Scikit-learnの機械学習では、決定木(Decision tree)という教師あり学習を利用することができます。
Scikit-learnで機械学習(決定木)
決定木は、予測対象をある閾値で段階的に分類していき、最終的な答えを導出する方法です。この分類構造が木のように見えることから決定木と呼ばれています。
mport pandas as pd
from sklearn import tree, metrics
from sklearn.model_selection import train_test_split
import pydotplus as pdp
from sklearn.externals.six import StringIO
csv = pd.read_csv('iris.csv')
csv_data = csv[["SepalLength","SepalWidth","PetalLength","PetalWidth"]]
csv_label = csv["Name"]
train_data, test_data, train_label, test_label = \
train_test_split(csv_data, csv_label, test_size=0.3, random_state=1)
clf = tree.DecisionTreeClassifier()
clf.fit(train_data,train_label)
pre = clf.predict(test_data)
cl_report = metrics.classification_report(test_label, pre)
print('正解率=', ac_score)
print(cl_report)
dot_data = StringIO()
tree.export_graphviz(clf, out_file=dot_data)
graph = pdp.graph_from_dot_data(dot_data.getvalue())
graph.write_png("iris_decisiontree.png")分類器にはtree.DecisionTreeClassifier()を設定しています。分類器の調整パラメータ(またはハイパーパラメータ)は与えずに、デフォルトのままで分類させてみます。
このトライアルは、105個のアヤメのデータを用いた教師あり学習になります。
正解率= 0.955555555556
precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 14
Iris-versicolor 0.94 0.94 0.94 18
Iris-virginica 0.92 0.92 0.92 13
avg / total 0.96 0.96 0.96 45正解率は95.55%に達しており、かなりの精度で分類できていることがわかります。setosa(セトサ)は100%判別できています。versicolor(バージカラー)とvirginica(バージニカ)は判別が難しいものもあるようです。これは、前回の主成分分析で確認したデータの特徴と同じです。
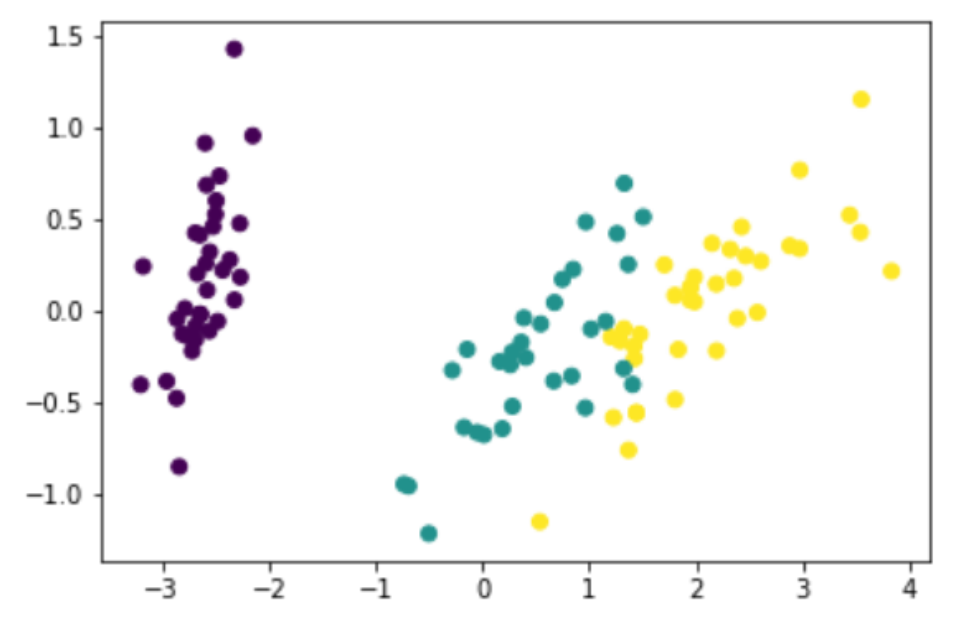
この結果から解ることは、setosa(セトサ)は紫色のプロットで、右側で一部重なり合っているのがversicolor(バージカラー)とvirginica(バージニカ)ということになります。
どのような決定木で分類されているのか確認してみましょう。
dot_data = StringIO()
tree.export_graphviz(clf, out_file=dot_data)
graph = pdp.graph_from_dot_data(dot_data.getvalue())
graph.write_png("iris_decisiontree.png")決定木を可視化するには、pydotplusとgraphvisが必要となります。pydotplusはpipでインストールできます。graphvisは環境によりインストール方法が異なりますが、RHELやCentOS系のlinuxならyumでインストールすることができます。
先ほどの学習で作成された決定木は以下の通りです。
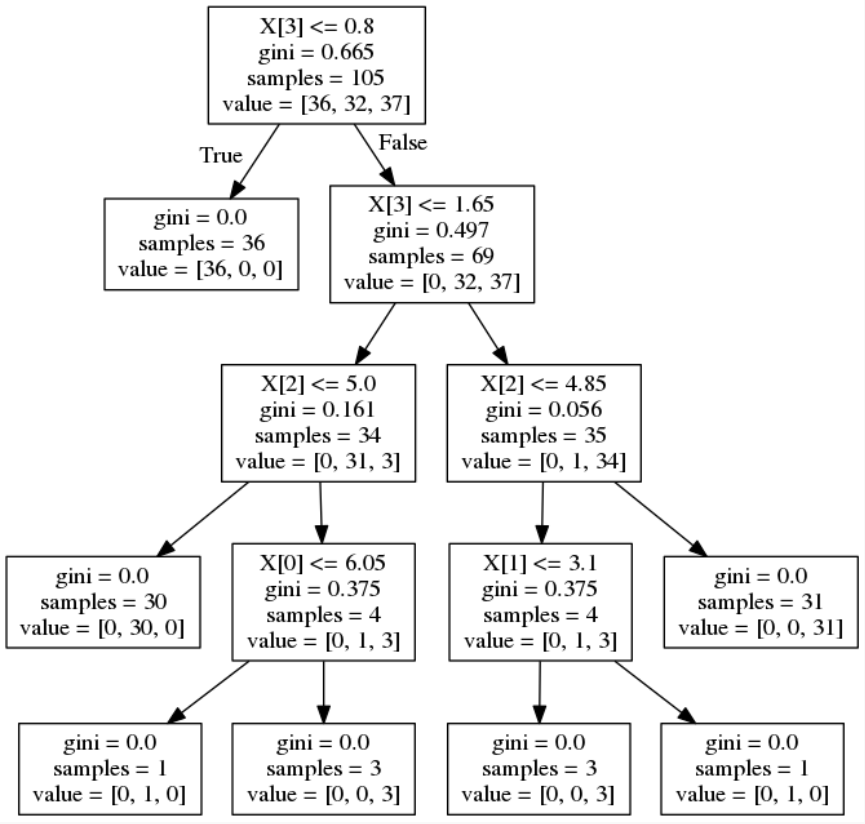
一番上段がスタート位置で、条件に対して左にTrue、右にFalseで判別が進んでいきます。今回の実験では、X[0]ががくの長さ、X[1]ががくの幅、X[2]が花びらの長さ、X[3]が花びらの幅となっています。
setosa(セトサ)というアヤメは100%分類できました。決定木では一階層目の花びらの幅が0.8以下という分類だけで判別できるということになっています。
決定木は、判別する階層を指定することも可能です。分類器の調整パラメータ(ハイパーパラメータ)に「max_depth=階層」と設定します。
clf = tree.DecisionTreeClassifier(max_depth=2)正解率= 0.955555555556
precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 14
Iris-versicolor 0.94 0.94 0.94 18
Iris-virginica 0.92 0.92 0.92 13
avg / total 0.96 0.96 0.96 45正解率に変化はないようです。決定木はどうなったでしょうか。
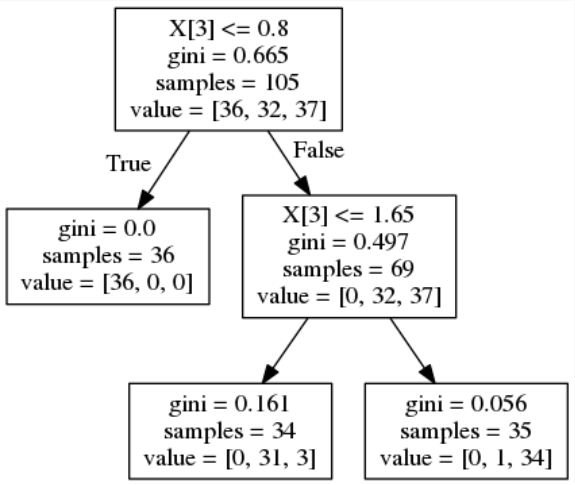
決定木は、デフォルトでは4階層でしたが、ハイパーパラメータで2階層に設定したので、決定木が2階層で出力されました。versicolor(バージカラー)とvirginica(バージニカ)は、花びらの幅が1.65以上か未満で大体分類できるようです。
機械学習や深層学習などの人工知能(AI)は、答えがどのように導出されたかは一般的にブラックボックスになっています。AI開発を進めていく上で、この問題がビジネスの障壁になってくることが少なくありません。
一方、決定木では人の思考や判断と同じレベルで比較できるため、受け入れられやすいかもしれません。
まずは、データ分析のやり方をしっかり身に着けることを心掛けましょう。
