
Keras+TensorFlowで実践CNN(その2)
CNNで被写体を識別する
前回は、CNN(畳み込みニューラルネットワーク)に入力する画像データを作成しました。画像データの加工方法については、以下を確認してください。
今回は、実際に作成した画像データを使用して、被写体をCNNで画像識別できるか実験します。まず始めにCNNについて図で確認しましょう。
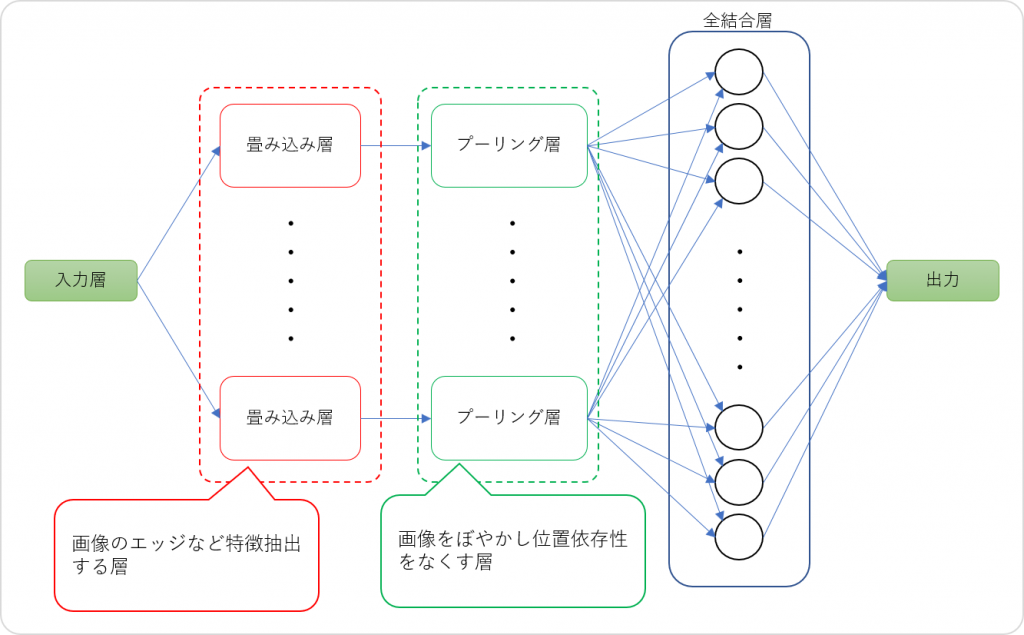
CNNのグラフは、入力層と出力層を除いて大きく3つの層で構成します。
畳み込み層は、入力され元画像について、平滑化やエッジ(濃淡など)の検出処理を行い、指定されたパターン数分の特徴マップを作成します。これにより、画像が持つ局所的特徴を抽出しています。
プーリング層は、画像をぼやかし、位置依存性をなくす処理を行うものです。畳み込み層で作成した特徴マップを縮小することにより、特徴量が多少ずれていたとしても、ズレを許容して識別することが可能となります。プーリングの方法には、最大プーリングと平均プーリングがあります。
全結合層は、畳み込み層やプーリング層から得られた2次元の特徴マップを1次元に展開する処理を行います。ここで識別を行うために必要な多重ニューロンを作成し、特徴量に重みやバイアスを更新したり、誤差逆伝搬法で誤差を更新したりする処理を行います。
モノクロスケールの画像から動物を識別する
では、モノクロスケールの画像から動物を識別するCNNを作成してみます。
import keras
from keras.models import Sequential
from keras.layers import Convolution2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
from keras.utils.visualize_util import plot
import numpy as np
import sys
categories = ["panda","wild_cat","rhino","elephant","flamingo","platypus","okapi","llama","kangaroo","hedgehog","emu","beaver"]
num_class = len(categories)
img_width = 64
img_height = 64
#読み込んだ画像データを正規化する
train_data, test_data, train_label, test_label = np.load("./images/wildlife_gray.npy")
train_data = train_data.astype("float32") / 256
test_data = test_data.astype("float32") / 256
#グレースケール画像をConvolutio2Dに入力するための次元操作
train_newarray = (train_data.shape[0], train_data.shape[1], train_data.shape[1], 1)
train_data = np.reshape(train_data, train_newarray)
test_newarray = (test_data.shape[0], test_data.shape[1], test_data.shape[1], 1)
test_data = np.reshape(test_data, test_newarray)
#モデルの設定
model = Sequential()
#畳み込み層の設定
model.add(Convolution2D(32, 3, 3, border_mode='same',
input_shape=train_data.shape[1:], name='Conv2D-1'))
model.add(Activation('relu'))
#プーリング層の設定
model.add(MaxPooling2D(pool_size=(2,2),name='MaxPool-1'))
model.add(Dropout(0.25, name='Dropout-1'))
#全結合層の設定
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5, name='Dropout-2'))
#出力層の設定
model.add(Dense(num_class, input_dim=512))
model.add(Activation('softmax'))
#モデルの構築
model.compile(loss = 'binary_crossentropy',
optimizer = 'rmsprop',
metrics = ['accuracy'])
#モデルプロットとTensorBoardの出力設定
plot(model, to_file="model.png", show_shapes=True)
log_filepath = "./log_dir/"
tb_cb = keras.callbacks.TensorBoard(log_dir=log_filepath, histogram_freq=1,
write_graph=True, write_images=True)
#学習実行
model.fit(train_data, train_label, verbose=1, callbacks=[tb_cb],
nb_epoch=50, batch_size=2)
#validation_data=(test_data,test_label))
#テストデータで評価する
score = model.evaluate(test_data, test_label, verbose=0)
print("loss=", score[0])
print("accuracy=", '{0:.2f}'.format(score[1]))KerasのConvolution2Dへの入力は4次元テンソルです。RGB画像のシェープは、(入力画像数、縦ピクセル、横ピクセル、RGBレイヤ数)で構成されていますが、グレースケール画像の場合は、(入力画像数、縦ピクセル、横ピクセル)となっています。このままでは、グレースケール画像をConvolution2Dに入力できないので、画像データの次元変換をnp.reshape()メソッドで行っています。
#グレースケール画像をConvolutio2Dに入力するための次元操作
train_newarray = (train_data.shape[0], train_data.shape[1], train_data.shape[1], 1)
train_data = np.reshape(train_data, train_newarray)
test_newarray = (test_data.shape[0], test_data.shape[1], test_data.shape[1], 1)
test_data = np.reshape(test_data, test_newarray)上記の次元変換で、グレースケール画像のシェープが(入力画像数、縦ピクセル、横ピクセル、1)に変換されるので、問題なくConvolution2Dに入力できるようになります。
モデルは、畳み込み層から全層結合層がそれぞれ1回だけ設定されています。
#モデルの設定
model = Sequential()
#畳み込み層の設定
model.add(Convolution2D(32, 3, 3, border_mode='same',
input_shape=train_data.shape[1:], name='Conv2D-1'))
model.add(Activation('relu'))
#プーリング層の設定
model.add(MaxPooling2D(pool_size=(2,2),name='MaxPool-1'))
model.add(Dropout(0.25, name='Dropout-1'))
#全結合層の設定
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5, name='Dropout-2'))
#出力層の設定
model.add(Dense(num_class, input_dim=512))
model.add(Activation('softmax'))畳み込み層では、32個の特徴マップを配置し、重みは3×3のフィルタを設定しています。
プーリング層は、特徴マップの縦横が1/2(pool_size=(2,2))になるようダウンスケーリングし、最大プーリングを出力するように設定しています。また、プーリング層では、25%のドロップアウトを設定して、過学習を防止する効果を入れていきます。
全結合層では、特徴マップを1次元に展開し、512個のノードに分割して出力層に結合しています。また、全結合層では、50%のドロップアウトを設定しています。最終的にソフトマック関数で確率配分した結果が出力層に出力されるグラフになっています。
モデルの構造は、プロット図にすることで各層への入出力のシェープや並びを一目で確認することができます。
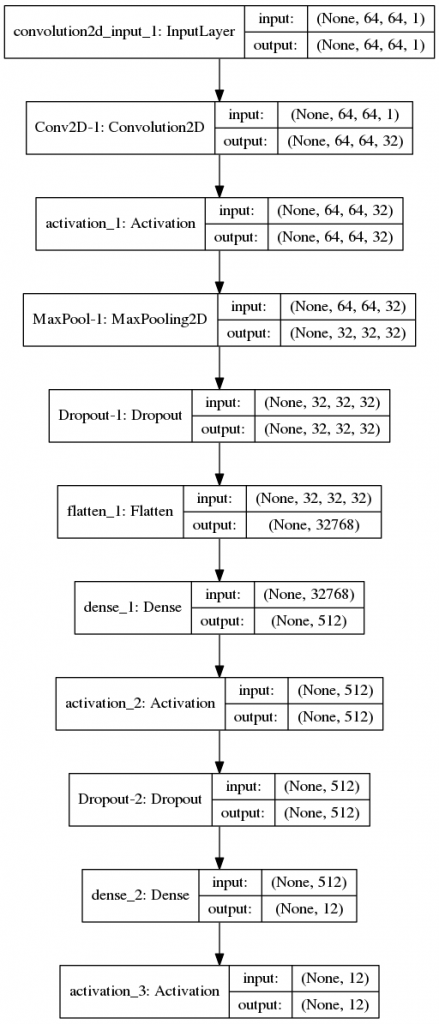
今回の作成した動物のグレースケール画像に対するCNNの学習と検証結果は以下の通りとなりました。
Epoch 43/50
456/456 [==============================] - 65s - loss: 0.0033 - acc: 0.9993
Epoch 44/50
456/456 [==============================] - 65s - loss: 1.3466e-07 - acc: 1.0000
Epoch 45/50
456/456 [==============================] - 65s - loss: 2.5860e-05 - acc: 1.0000
Epoch 46/50
456/456 [==============================] - 65s - loss: 4.7654e-07 - acc: 1.0000
Epoch 47/50
456/456 [==============================] - 65s - loss: 1.1960e-06 - acc: 1.0000
Epoch 48/50
456/456 [==============================] - 65s - loss: 7.1424e-07 - acc: 1.0000
Epoch 49/50
456/456 [==============================] - 65s - loss: 3.9840e-07 - acc: 1.0000
Epoch 50/50
456/456 [==============================] - 65s - loss: 1.3723e-07 - acc: 1.0000
loss= 0.775577879834
accuracy= 0.90エポック数の終盤では、正解率が100%になっています。また、テストデータによる検定では、正解率が90%となりました。
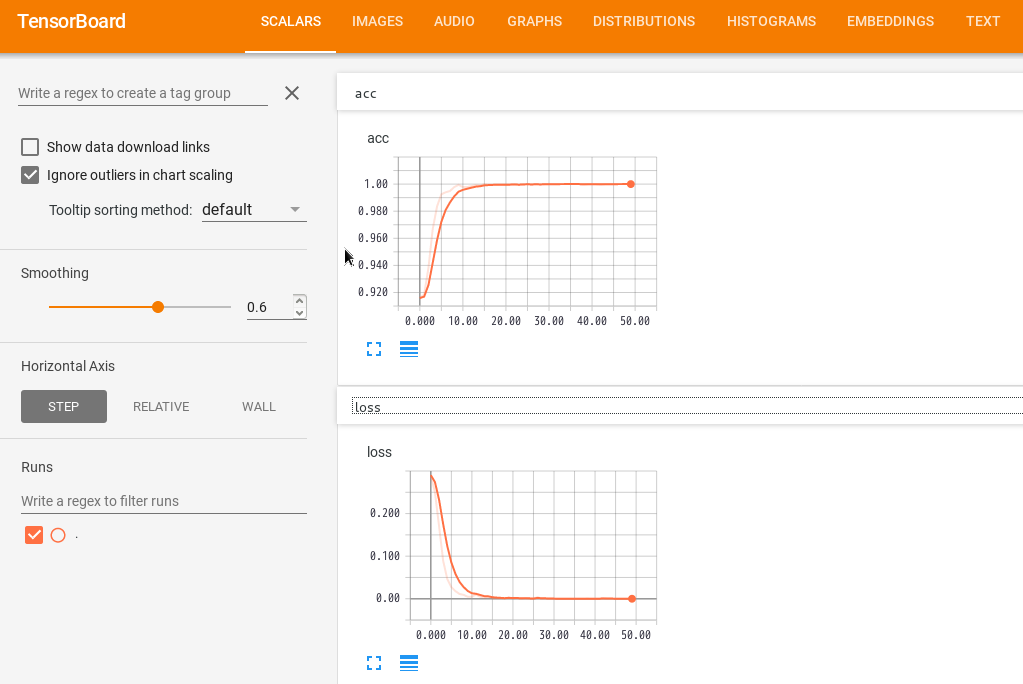
学習中の正解率(上)と損失のグラフ(下)を見る限り、学習自体はうまくできているようですが、テスト用データによるの損失の大きさと正解率と比べると乖離が大きいので、過学習の可能性があるかもしれません。しかしながら、入力した画像の解像度が荒く、CNNの層も浅いことを考えると、この実験レベルではなかなかの成果ではないでしょうか。
今回は、グレースケールの画像データを用いてCNNによる画像識別の実験を行いました。次回は、RGB画像(カラー)画像を用いてCNNによる画像識別の実験を行いたいとおもいます。