
TensorFlowで実践ディープラーニング(その3)
目次
ディープラーニングをもっとお手軽に
ディープラーニングとは、一言で表すと「複数の隠れ層が多数存在するニューラルネットワーク」ということです。
今回は、隠れ層を増やしてディープラーニングを実験していきますが、「Keras」を使って、もう少しお手軽にディープラーニングの実験をやってみようとおもいます。
Kerasは、Pythonで記述されたオープンソースのニューラルネットワークライブラリで、TensorFlowの上位APIとしてシームレスに連携することが可能です。「Kras」は、ディープラーニングに対する高い生産性、手軽さ及び柔軟性を兼ね備えており、エンタープライズと研究コミュニティの両方から注目を集めているAPIです。
では、Kerasを使うとどのくらいお手軽になるのか、実際に実験してみましょう。
Kerasでアヤメをディープラーニングする
この実験で使用したライブラリなどの組み合わせは、以下の通りです。
① python 3.6.2
② TensorFlow 1.2.1
③ Keras 1.2.1
Pythonコードを書いてみましょう。
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
import keras
from keras.models import Sequential
from keras.layers.core import Dense, Activation
from keras.utils import np_utils
csv = pd.read_csv('iris.csv')
iris_class = {'Iris-setosa': 0, 'Iris-versicolor': 1, 'Iris-virginica': 2}
csv["Name"] = csv["Name"].apply(lambda x : np.array(iris_class[x]))
csv_data = csv[["SepalLength","SepalWidth","PetalLength","PetalWidth"]]
csv_label = csv["Name"]
train_data, test_data, train_label, test_label = \
train_test_split(csv_data, csv_label, test_size=0.3, shuffle=True)
#Pandasで読み込んだCSVは、Kerasに直接入力できないため、numpy.ndarrayに変換する
train_data = train_data.values
train_label = np_utils.to_categorical(train_label.values)
test_data = test_data.values
test_label = np_utils.to_categorical(test_label.values)
#モデルの定義
model = Sequential()
#入力層-隠れ層1の設定
model.add(Dense(4, input_dim=4))
model.add(Activation('sigmoid'))
#隠れ層1-隠れ層2の設定
model.add(Dense(4, input_dim=4))
model.add(Activation('sigmoid'))
##隠れ層2-出力層の設定
model.add(Dense(3, input_dim=4))
model.add(Activation('softmax'))
#TensorBoardに表示するための設定
log_filepath = "./log_dir/"
tb_cb = keras.callbacks.TensorBoard(log_dir=log_filepath, histogram_freq=1,
write_graph=True, write_images=True)
#モデルを構築する
model.compile(loss = 'categorical_crossentropy',
optimizer = 'sgd',
metrics = ['accuracy'])
#モデルを訓練する
model.fit(train_data, train_label, verbose=1, callbacks=[tb_cb],
nb_epoch=200, batch_size=1,
validation_data=(test_data,test_label))
#テストデータで評価する
score = model.evaluate(test_data, test_label, verbose=0)
print("loss=", score[0])
print("accuracy=", '{0:.2f}'.format(score[1]))上記では、「入力層」-「隠れ層1」-「隠れ層2」-「出力層」の多層構造型ニューラルネットワークを定義しています。隠れ層が2層存在するグラフであるため、ディープニューラルネットワーク(DNN)と言うことができます。
ハイパーパラメータの設定をデフォルト設定とするならば、このくらいのステップ数でディープラーニングができてしまいます。Kerasのコーディングは、TensorFlowよりもはるかにお手軽になっていることが理解できました。
Kerasに入力可能なデータの形成
Kerasに入力するデータを作成するポイントについて説明します。
csv = pd.read_csv('iris.csv')
iris_class = {'Iris-setosa': 0, 'Iris-versicolor': 1, 'Iris-virginica': 2}
csv["Name"] = csv["Name"].apply(lambda x : np.array(iris_class[x]))
csv_data = csv[["SepalLength","SepalWidth","PetalLength","PetalWidth"]]
csv_label = csv["Name"]
train_data, test_data, train_label, test_label = \
train_test_split(csv_data, csv_label, test_size=0.3, shuffle=True)
#Pandasで読み込んだCSVは、Kerasに直接入力できないため、numpy.ndarrayに変換する
train_data = train_data.values
train_label = np_utils.to_categorical(train_label.values)
test_data = test_data.values
test_label = np_utils.to_categorical(test_label.values)pandasのread_csv()メソッドを使用して、アヤメのデータ(iris-dataset.csv)を読み込みます。このデータから、がくと花びらの長さと幅及び花の名前を、それぞれの変数に代入します。
train_test_split()メソッドを使用して、訓練用データとテスト用データに分割します。
Kerasは、pandasのデータを直接読み込むことができないため、numpyの配列(numpy.ndarray)に変換します。numpyの配列への代入は、train_data.valuesとします。他のデータも同じように変換していきます。
訓練用とテスト用のラベルデータは、花の名前から「0,1,2」に変換しました。これを更にOne-hotベクトルに変換していきます。One-hotベクトルは、1-of-K表現とも呼ばれるもので、1つだけ「1」であとは全て「0」で表される配列です。
例えば、3種類のアヤメの場合、0は[1 0 0]、1は[0 1 0]、2は[0 0 1]と表現されます。One-hotベクトルは、np_utils.to_categorical()メソッドによって、データ個数に従い自動的に変換可能です。とても便利なメソッドです。
DNNモデルを構築する
次に、多層構造型ニューラルネットワークのモデル設定について説明します。
#モデルの定義
model = Sequential()
#入力層-隠れ層1の設定
model.add(Dense(4, input_dim=4))
model.add(Activation('sigmoid'))
#隠れ層1-隠れ層2の設定
model.add(Dense(4,input_dim=4))
model.add(Activation('sigmoid'))
#隠れ層2-出力層の設定
model.add(Dense(3, input_dim=4))
model.add(Activation('softmax'))
#TensorBoardに表示するための設定
log_filepath = "./log_dir/"
tb_cb = keras.callbacks.TensorBoard(log_dir=log_filepath, histogram_freq=1,
write_graph=True, write_images=True)
#モデルを構築する
model.compile(loss = 'categorical_crossentropy',
optimizer = 'sgd',
metrics = ['accuracy'])Sequential()メソッドで、設定した順序に従ってモデル内の層(レイヤー)を構築することを宣言しています。また、model.add()メソッドでモデル内に層の設定を追加していきます。
Dense()メソッドでは、第1引数に下流の層のノード数を設定し、第2引数に入力値の次元数を設定します。
Activation()メソッドでは、活性化関数を設定します。ここでは、入力層から隠れ層の間はsigmoid関数、隠れ層から出力層の間ではsoftmax関数を設定しています。Keras2のsoftmax関数は、tf.nn.softmax(x,axis)に変更されているためエラーが出ることがあるようですので注意してください。
最後にcompile()メソッドで設定したモデル条件に従ってモデルを構築します。compile()メソッドでは、損失関数やオプティマイザを設定することができます。
モデルを訓練してみる
では、構築したモデルを訓練させてテストデータで評価してみましょう。
#TensorBoardに表示するための設定
log_filepath = "./log_dir/"
tb_cb = keras.callbacks.TensorBoard(log_dir=log_filepath, histogram_freq=1,
write_graph=True, write_images=True)
#モデルを訓練する
model.fit(train_data, train_label, verbose=1, callbacks=[tb_cb],
nb_epoch=200, batch_size=1,
validation_data=(test_data,test_label))
#テストデータで評価する
score = model.evaluate(test_data, test_label, verbose=0)
print("loss=", score[0])
print("accuracy=", '{0:.2f}'.format(score[1]))Kerasで構築したモデルについてもTensorBoardを使用して可視化することができます。keras.callbacks.TensorBoard()メソッドで必要事項を設定して、fit()メソッドのcallbacks引数に与えれば完了します。
fit()メソッドには、訓練用データと訓練用データの他にエポック数(nb_epoch)とバッチ数(batch_size)を設定することで、学習回数などを設定することができます。
エポック数は、「1つの訓練用データを何回反復学習するか」を示しています。また、バッチ数は、勾配の更新を行うサンプル数の単位を示しています。
上記では、batch_size=1であるためすべての訓練用データ毎に勾配を更新していきます。バッチ数を少なくすると計算速度が向上しますが、その場合は損失関数が小さくなるとは限りません。
エポック数とバッチ数の調整は、訓練用データの全体量と計算リソースに応じて適切に設定すべきものですので、決まりはないものと理解してください。
では、予測精度を見てみましょう。
105/105 [==============================] - 0s - loss: 0.1391 - acc: 0.9714 - val_loss: 0.1543 - val_acc: 0.9556
Epoch 196/200
105/105 [==============================] - 0s - loss: 0.1276 - acc: 0.9810 - val_loss: 0.1701 - val_acc: 0.9556
Epoch 197/200
105/105 [==============================] - 0s - loss: 0.1362 - acc: 0.9714 - val_loss: 0.1473 - val_acc: 0.9778
Epoch 198/200
105/105 [==============================] - 0s - loss: 0.1343 - acc: 0.9619 - val_loss: 0.1468 - val_acc: 0.9778
Epoch 199/200
105/105 [==============================] - 0s - loss: 0.1337 - acc: 0.9714 - val_loss: 0.1460 - val_acc: 0.9778
Epoch 200/200
105/105 [==============================] - 0s - loss: 0.1274 - acc: 0.9810 - val_loss: 0.1518 - val_acc: 0.9556
loss= 0.151751035121
accuracy= 0.96200回の反復訓練で正解率は98.1%に到達しました。また、テスト用データによる交差検定でも、正解率は96%となりました。ここから更に精度を上げていくためには、損失関数や活性化関数を変更したり、過学習が起こっていないか確認したり、ハイパーパラメータをチューニングしたりしていく必要があります。ディープラーニングのチューニングは職人技と言われる理由もわかるような気がします。
次に、TensorBoardで学習状態を見確認してみましょう。
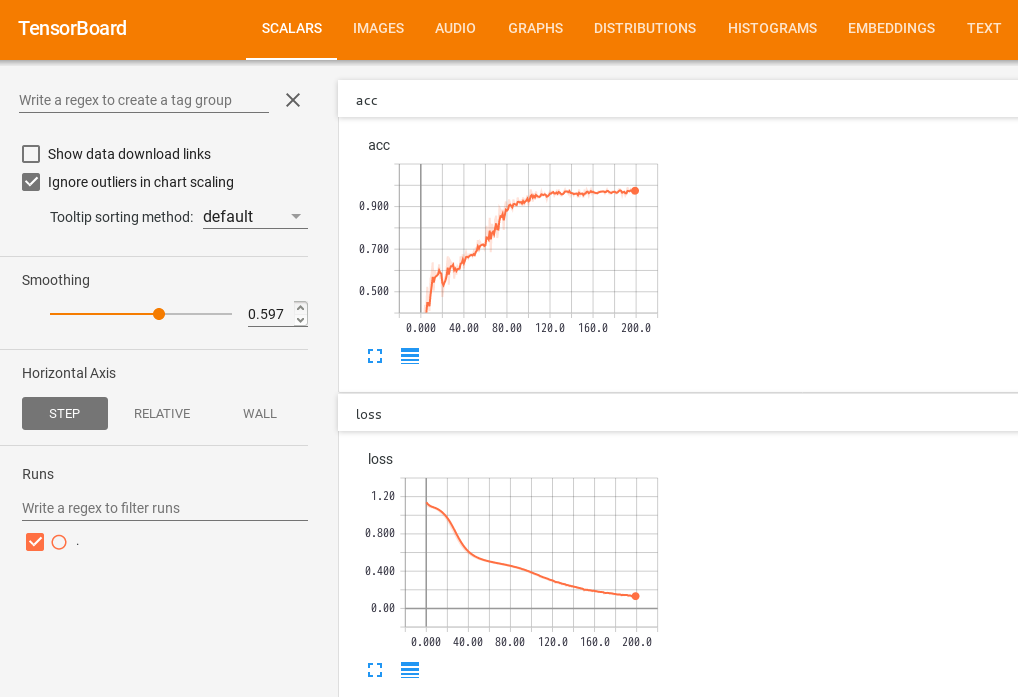
TensorBoardのダッシュボードから「SCALARS」のタブをクリックすると、200回の反復訓練における正解率の変化と損失関数の変化を確認することができます。
チューニングする際は、このグラフの形を見ることが重要です。今回のようなグラフの形状であれば、まあまあ良く学習できたと判断してもよさそうです。
途中で損失関数や正解率が逆行するような場合は、過学習(Over fitting)が起こっているかもしれません。そんな時は、学習用データの性質(主成分とノイズ)などについて検討していく必要があります。
今回のまとめ
今回は、KerasとTensorFlowを使って、深層学習(ディープラーニング)を実験しました。
Kerasのおかげで、技術者は複雑なコーディングから解放され、ディープラーニングに対して集中することができるようになり、生産性が飛躍的に向上しました。
今後ますますディープラーニングなど人工知能(AI)が加速的に社会に広まり浸透していくことでしょう。人工知能(AI)のマーケットは、2020年度では1兆円規模、次いで2030年度には2兆円規模の需要が予測されています。人工知能(AI)のコモディティ化に伴い、Kerasへの期待も今後益々高まっていくことでしょう。